

Your sequences are sharp, value proposition: clear and your SDRs are trained and executing. Yet open rates are falling, pipeline reviews feel like archaeology digs, and quarterly targets keep slipping. The bottleneck is not strategy, messaging, or talent. It is CRM data stewardship, or the lack of it. Beneath every underperforming outbound motion is a contact database silently rotting from the inside.
B2B contact data decays at roughly 30% per year. Executives change roles. Departments restructure. Companies get acquired. But your database stays frozen. If your CRM was last enriched 18 months ago, a significant portion of your outreach is reaching people who have moved on, organizations that no longer exist, and titles that no longer reflect reality.
The fix is not a one-time data purchase. It is a fundamental shift in how you treat your CRM: not as a static repository, but as a living intelligence system that requires continuous stewardship.
The Revenue Cost of Poor CRM Data Stewardship
Most revenue teams measure data quality by what is visible: bounced emails, disconnected phone numbers, undeliverable mail. These are symptoms. The structural damage runs deeper.
When outbound campaigns hit invalid addresses at scale, email service providers flag your domain. A bounce rate above 2% triggers deliverability warnings. At 5% or higher, you risk landing in spam for your entire list, including valid contacts. One stale segment contaminates your entire outbound engine and takes months to recover from.
The human cost compounds the technical one. SDRs spend hours personalizing outreach. When the contact left the company six months ago, that effort produces nothing: no meeting, no opportunity, no pipeline entry. Repeated dead ends erode rep confidence in the data and, eventually, in the entire GTM process.
The financial math is equally stark. A team of 10 SDRs making 60 calls per day, where 25% of target accounts carry outdated decision-maker data, burns over 150 misallocated calls daily. At a fully-loaded SDR cost of $80,000 per year, that is a six-figure annual leak from bad data alone, before accounting for pipeline that was never created.
Live Enrichment: The Core of Continuous CRM Data Stewardship
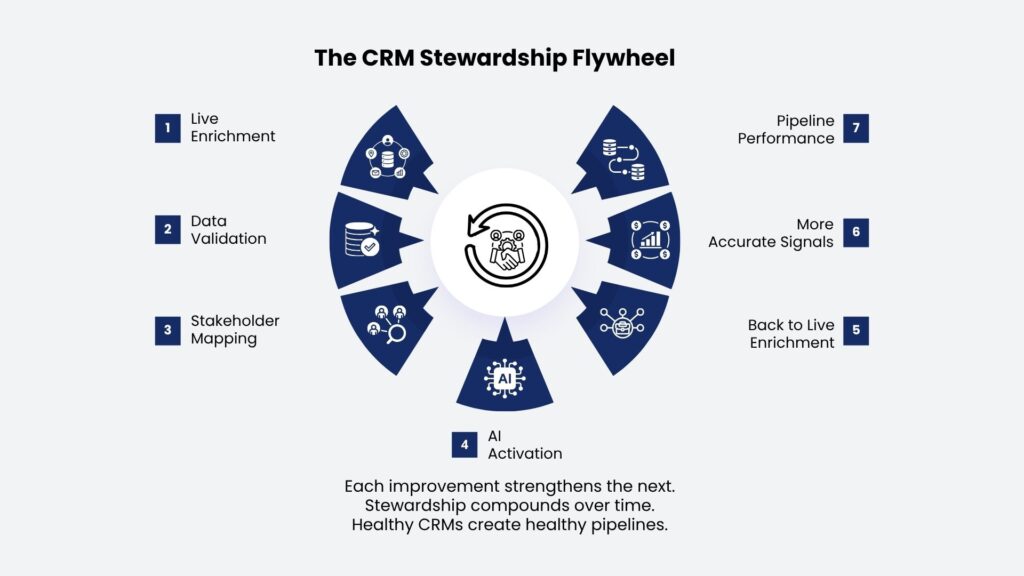
The traditional enrichment model looks like this: buy a list, import it, run campaigns, watch it decay, repeat in 18 months. This treats data as a product. The more accurate framing is that data is a process, one that requires ongoing maintenance to stay commercially viable.
Live enrichment replaces periodic snapshots with continuous monitoring. AI-powered systems track signals across the web: LinkedIn activity, job board changes, press releases, company filings, firmographic updates. When a key contact changes roles, the CRM record updates automatically and triggers an alert to the owning rep.
Consider a familiar enterprise sales scenario. Your AE has been nurturing a VP of Engineering for six months. A relationship is forming. Then, quietly, that VP moves to a competitor. A static CRM does not flag this. Your rep sends a follow-up, gets no response, and assumes the deal has stalled. Meanwhile, the incoming VP has different priorities, a fresh budget, and no relationship with your team. The window to establish context is narrow and entirely invisible to your revenue organization.
That is the gap live enrichment closes. When a contact changes roles, even internally, the system notifies the rep: your contact has moved, would you like to re-engage or identify their successor? That is pipeline preservation, not data management. Teams using continuous enrichment report measurably higher deliverability and connect rates, because live data enables outreach triggered by actual market signals rather than spray-and-pray cadences built on stale information.
The Stakeholder Gap: What Your CRM Does Not Show You
Beyond stale data lies a subtler and more expensive problem: the stakeholders who were never in your CRM to begin with.
Research on enterprise buying behavior consistently shows that B2B purchases involve between six and ten decision-makers. The average CRM record for a target account contains one to two contacts. That is not just a coverage gap. It is a strategic vulnerability.
Imagine your team is working an account in the logistics sector. Your primary contact is the VP of Operations, a strong champion. What your CRM does not show: the CFO controls discretionary technology spend above $50,000, the Head of IT Security must sign off on any SaaS deployment, and the COO recently mandated a vendor consolidation initiative. Your champion is supportive. But without visibility into the full buying committee, your deal stalls in procurement. A competitor builds relationships with the CFO. The opportunity dies in a meeting you did not know was happening.
A structured gap analysis answers a precise question: for each target account in your CRM, who is missing?
The process involves mapping the typical buying committee for your ICP by vertical and deal size, auditing existing contacts by role rather than volume, and using enrichment to surface and verify missing stakeholders. Organizations that engaged full buying committees saw significantly higher win rates and shorter sales cycles compared to those running single-threaded account coverage. The deal risk is never the contacts you have. It is always the contacts you are missing.
Prioritize gap analysis on active pipeline accounts first. Gaps in closed-won deals are a learning exercise. Gaps in live opportunities are a revenue risk.
Why AI Performance Starts with CRM Data Quality
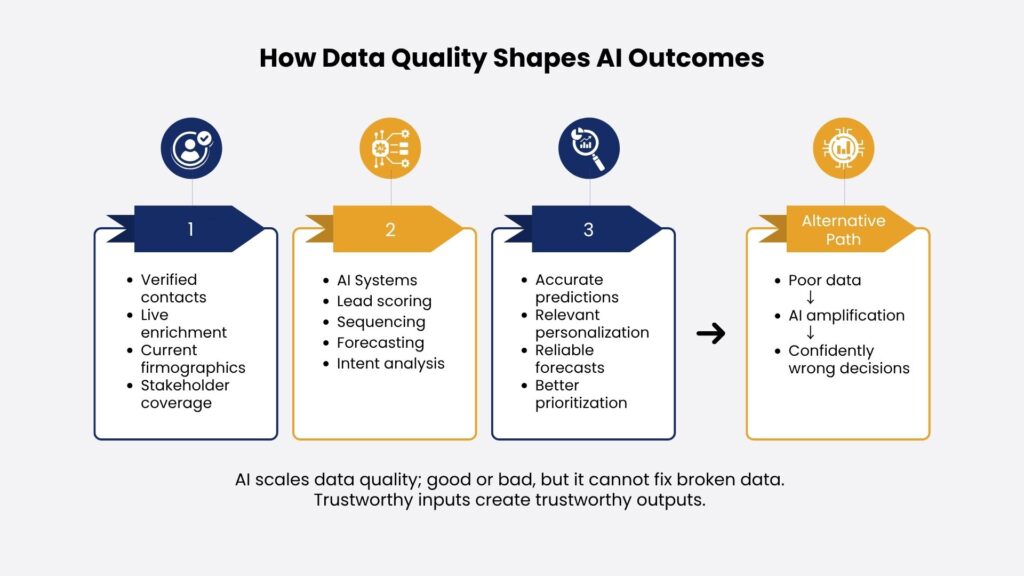
There is a more urgent reason to treat data quality as a strategic priority: your AI tools are only as good as the data they run on.
Revenue teams are investing heavily in AI-powered sequencing, lead scoring, intent analysis, and pipeline forecasting. The assumption is that model sophistication drives output quality. In practice, output quality is almost entirely a function of input data quality.
An intent scoring model analyzing 18-month-old firmographic data learns the wrong patterns. A personalization engine pulling from unverified contact records produces off-target messaging that signals you do not actually know who you are writing to. A pipeline forecast built on contacts who have since left their companies overstates deal confidence until those opportunities collapse late in the quarter.
AI amplifies what it is given. If your data is bad, AI makes you confidently wrong, faster.
The revenue teams seeing the strongest returns from AI investment share one infrastructure decision: they built data quality before layering on AI capabilities. Their CRMs are continuously enriched, buying committees are mapped, and contact data is validated against live sources. When AI tools generate scoring signals or sequence recommendations, those outputs reflect current market reality. The competitive advantage does not come from the AI alone. It comes from AI operating on trustworthy data.
A Practical Framework for CRM Database Stewardship
Treating database stewardship as a continuous operational discipline requires four sustained commitments.
Live Enrichment: Replace the annual list purchase with a continuous monitoring layer that detects role changes, company transitions, and email validity in real time. The cost delta is marginal. The compounding accuracy advantage is substantial.
Gap Analysis: Make buying committee coverage a standard account review metric. If a deal reaches a mid-stage gate with only one contact in the account, trigger an automatic gap-fill workflow before the pipeline meeting.
Data Hygiene: Run automated validation at the intake layer before records reach active pipelines. Route any contact with high bounce risk or incomplete role data into an enrichment track. Stop letting unverified data contaminate your primary workspace.
AI Alignment: Define a minimum data quality threshold before contacts enter AI-powered sequences: verified email, confirmed current role, enriched firmographics. Gate AI activation on data quality, not campaign urgency.
Assign explicit ownership of CRM health to RevOps. Data quality degrades when it is everyone’s problem and therefore no one’s priority.
Conclusion: The Revenue Engine Is the Data Engine
The most durable competitive advantage in demand generation is not your messaging framework or your technology stack. It is the quality and completeness of your commercial intelligence: knowing who the right buyers are, where they are now, and what has changed since the last time you spoke.
The organizations building sustainable pipeline are not the ones with the largest databases. They are the ones whose data is the most current, the most complete, and the most trustworthy. They have stopped treating data acquisition as the finish line but instead treat it as the starting point.
As AI-powered selling becomes standard, differentiation will shift toward the quality of the data those systems operate on. Teams running continuous stewardship will reach the right inboxes, deploy reps against real opportunities, and generate AI outputs worth acting on. Those running on stale data will spend more, reach fewer, and close less.
Your CRM is not a historical archive. It is the commercial foundation of your revenue engine. The difference between a graveyard and an engine is not the amount of data you have. It is how rigorously you maintain, enrich, and activate it.


